The Guardrails page is available on the Pro plan and above — the Free plan has no access. Creating, editing, or deleting a guardrail additionally requires the Scale plan; on Pro and Team you can view existing guardrails and their execution history, but mutating actions return an upgrade prompt.
How guardrails work
When your SDK is initialized withguardrails: true on a provider wrapper, it sends a check request to POST /v1/guardrails/check before the LLM call (pre-check) and after the LLM response (post-check). The backend evaluates all active policies for your project against the content and returns a verdict.
The SDK receives the verdict and either:
- Allows the call to proceed normally
- Blocks it by throwing a
GuardrailBlockedError - Redacts sensitive content and substitutes the cleaned text
- Warns (logs the trigger but allows the call through)
Creating a guardrail
1
Open the Guardrails page
Navigate to Guardrails in the left sidebar.
2
Click New guardrail
The guardrail creation dialog opens.
3
Name the guardrail
Give it a descriptive name that explains what it protects against, e.g.
block-competitor-mentions or toxicity-filter.4
Choose a guardrail type
Select the type of check to run. The dropdown lists each type by its identifier, shown here alongside what it does:
The following types apply specifically to agent traces — they inspect tool calls and agent names rather than raw prompt/response text:
Most types can run on pre-LLM checks, post-LLM checks, or both — see the next step for how to pick.
custom_llm is deprecated — Zespan steers new policies toward regex instead. It still works if you already have one configured, but prefer regex (or another pattern-based type above) for new guardrails.5
Configure the policy
Fill in the type-specific settings. For keyword-based types (topic boundary, scope enforcement, tool misuse allow/blocklists), enter the terms. For regex, enter the patterns. For toxicity and prompt-injection types, pick a sensitivity level (low/medium/high). For PII detection, choose a compliance preset and, optionally, fine-tune the confidence threshold under advanced detection. For custom LLM judge, write your evaluation prompt.
6
Set the action
Choose what happens when the guardrail triggers:
- Block — reject the request and throw
GuardrailBlockedErrorin the SDK - Redact — remove the matched content and use the cleaned text
- Warn — allow the request but surface the trigger as a warning
- Log — allow the request and record the trigger in execution history, without surfacing it as a warning (useful while you’re still tuning a new policy)
7
Choose check phases
Select whether the policy applies to pre-LLM checks (the prompt), post-LLM checks (the completion), or both.
8
Choose which agents it applies to
By default a guardrail applies project-wide — every trace in the project is checked against it. If you only want it enforced for specific agents (for example, a policy that should only run against your refund-processing agent, not your general chat agent), switch to Specific agents and add the agent names it should apply to. Traces from agents not in the list skip this guardrail entirely.
9
Save
Click Save. The policy activates immediately — all subsequent SDK check requests will include this policy.
Promoting a violation to a policy
Every guardrail hit recorded against a trace can become a permanent rule with one click, right from where it happened — no need to reconstruct the pattern from scratch.1
Open the trace
Find the trace with the violation you want to codify. The guardrail hit shows as its own span in the flame graph, colored to match its outcome.
2
Open the guardrail span
Click it to see the policy, the check phase, and the exact value that triggered it.
3
Click Promote to Policy
Zespan pre-fills a new guardrail draft with the same tool, field, and value that triggered the violation.
4
Review and save
Adjust the draft if you want — tighten a keyword list, change the action, scope it to specific agents — then save it like any other guardrail.
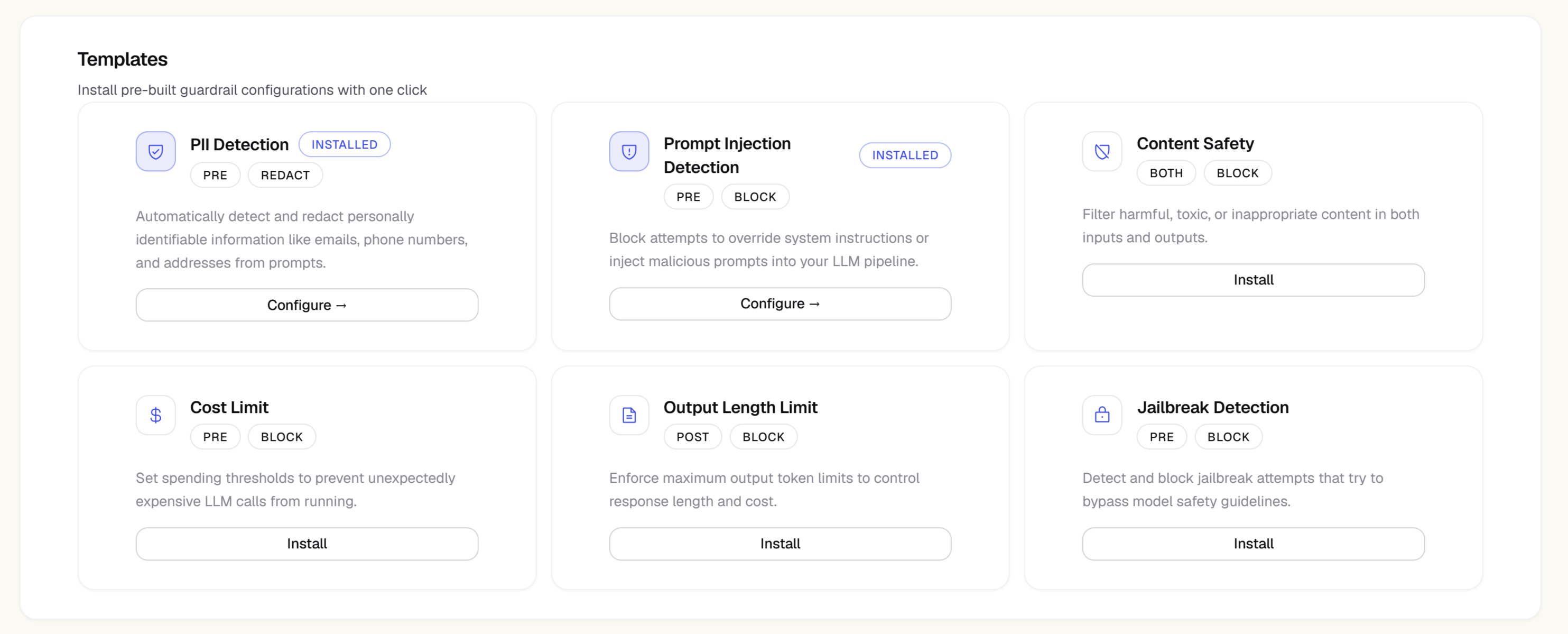
Guardrail templates
Instead of creating guardrails one at a time, you can bundle several rules into a reusable template and apply that bundle to a project (optionally scoped to specific agents, the same way a single guardrail can be). Zespan ships a set of preset templates that are managed and auto-updated with new threat patterns:
From the Templates tab you can:
- Apply a preset or a custom template to your project, project-wide or scoped to specific agents
- Clone a preset into an editable copy you can tweak (presets themselves can’t be edited or deleted)
- Create your own template from scratch by combining any of the guardrail types above into one bundle
- Edit or delete your own templates, and remove an application without deleting the template itself
Managing guardrails
The main Guardrails page shows a card for every configured policy, alongside a trend chart of block activity across all your guardrails. Each card shows:
Use the Status toggle to disable a guardrail without deleting it — disabled guardrails are skipped during checks.
Click through to a guardrail to open its detail page, with Configure, Test, and Logs tabs for editing settings, running the guardrail against sample text, and reviewing its recent trigger history.
Execution history
The main Guardrails page also includes a log of recent guardrail events (and each guardrail’s own Logs tab shows just its events), with:- Timestamp
- The guardrail and check phase (pre/post)
- The action taken (blocked, redacted, warned, logged)
- The reason the guardrail triggered (e.g. which PII types or keyword matched — not the full prompt)
- A link to the underlying trace
Testing a guardrail
Every guardrail (and the form for a new one) has a test panel where you can paste sample text and run it through the guardrail’s current configuration — this evaluates the real rule synchronously and returns a verdict, without needing a live trace from your application:- While creating a guardrail, the test panel runs against your unsaved draft settings
- On an existing guardrail’s Test tab, it runs against the saved configuration
- You can optionally supply a model name, operation name, estimated cost, and input token count — the cost ceiling type checks these directly
- The result shows an overall Allowed / Blocked verdict, the modified text (if a redact rule matched), and a per-guardrail breakdown of which rule fired, what action it took, whether it passed, and its latency
The test panel evaluates text content only. Agent-context checks that depend on the calling agent’s name or its recent tool calls — agent rate limit, tool misuse, loop detection, and delegation control — always pass in the test panel, since that context only exists on a real trace. Validate those types by checking their execution history after live traffic runs through them.
Latency impact
Guardrail checks add latency to your LLM calls. The check runs synchronously before (and optionally after) the LLM call. Typical check latency:Human approval gates
Beyond automatic block, redact, and warn actions, the SDK exposes a real human-in-the-loop primitive:awaitApproval() pauses execution until an admin approves or rejects the call from the dashboard — not just a log entry, an actual gate your code waits on.
Near-miss capture and suggested rules
Zespan also learns from traffic that almost triggered a numeric guardrail rule but didn’t. When a threshold-based check —cost_ceiling, agent_rate_limit, and similar types — evaluates close to its limit without firing, that near-miss is logged instead of silently discarded.
A background worker clusters recurring near-misses into suggested policy rules, surfaced in a panel on the Guardrails page: “Your agents have hit this pattern 6 times this week — no rule governs it yet. Want one?”
- Click Promote to Policy on a suggestion you agree with — it reuses the same promote flow described above
- Click Dismiss to clear a suggestion that isn’t worth a standing rule